I feel there is some slight mis-information in this article that might confuse people and give them the wrong impression of 'Local SSDs' vs the network based ones and about the nvme protocol and made it seem like "local ssd == nvme".
NVMe - 'non-volatile memory express'. This is a _protocol_ that storage devices like SSDs can use to communicate with the external world. It is orthogonal to whether the disk is attached to your motherboard via pcie, or it lives somewhere else in the datacenter and uses a different transport layer. For example, local NVME SSDs will use PCIe transport. But you can also have NVME-over-TCPIP, or NVME-over-fiber-channel. Or NVME-over-Fabrics. Many of these are able to provide significantly lower latencies than a millisecond.
As a concrete example, AWS `io2-express` has latencies of ~0.25-0.5ms, though i'm not sure which technology it's using.
nvme over fabrics: https://www.techtarget.com/searchstorage/definition/NVMe-ove... many interesting presentations on the official nvme website: https://nvmexpress.org/education/documents-and-videos/presen... aws: https://aws.amazon.com/blogs/storage/achieve-higher-database...
This reminds me of mirroring an SSD array to a HDD! I believe this is what some college kids get their hands on, since many motherboards come with 2 NVMEs. NVME RAID0 is too dangerous and RAID 1 is too expensive, but, by pouring few hundred more bucks, one can gain a marginal safety while enjoying the blazing fast RAID0.
The magic here is `--write-behind`/`--write-mostly`[1] in `mdadm`. I mean, that's the only method that I can think of here. This is an old dark magic that prevents (though not entirely) reading from a specific drive.
[1]: https://raid.wiki.kernel.org/index.php/Write-mostly
TBH, in general, I don't think it's a good option for databases. The slow drive does cause issues, for it is literally slow. The whole setup slows down when the write queue is full, reading from the write-mostly device can get be extremely slow thanks to all the pending writes, and the slow drive will wear out quicker thanks to the sustained high load (though this one should not apply in this specific case).
So you mostly don't want to use a single HDD as your mirror. For proper mirroring, you need another array of HDDs, which will end up being a NAS with its own redundancy. That's a large critical pain in the butt, but this is necessary for industrial grade reliability, and also allows making your "slow drive" faster in the future.
In this specific case, it's pretty well played. They get 4 billion messages per day, which is roughly 46k per second. Assuming each write requires updating at least one block - 4kb - the setup needs to sustain at least 185 MB/s, which is clearly beyond a single HDD. Google Persistent Disk is a kind of NAS anyway, so that perfectly aligns with the paragraph above.
Spinning rust isn't all that bad. I get 250 MB/s while sychronously (i.e. fsync/fdatasync) writing 384 GB to an Ultrastar DC HC550 (inside a WD Elements 18TB enclosure) connected via USB-3.
Spinning rust can get well above 185MB/s on a single disk if you're sequential.
And all random write workloads can be turned into sequential write workloads, either with clever design, or with something like logfs.
They are using a ScyllaDB, which is based on lsm trees, so all writes should already be sequential.
To me, this sounds like a GCP failure. The provider is supposed to provide you with options that you need. If you're going to build it yourself why bother with GCP?
It would be a fun exercise to reimplement Discord in AWS...or with FoundationDB.
In any case before revving the hardware I'd want to know how ScyllaDB actually is supposed to perform. I mean, their marketing drivel says this right on the main page: "Provides near-millisecond average latency and predictably low-single-digit P99 response times."
So why are they fucking with disks if ScyllaDB is so good? I mean, back in the day optimizing drive performance was like step 1. Inside tracks are faster, and make sure you don't saturate your SAS drives/Fiber Channel links by mistake. It's fun to do, but you could always get better performance by getting the software to not do dumb stuff. Seriously.
>So why are they fucking with disks if ScyllaDB is so good?
The database layer isn't magic. The database can't give you low-single-digit P99 response times, if a single I/O request can stall for almost 2ms.
That said, I don't think AWS would fare any better here as the infrastructure issue is the same. Networked EBS drives on AWS are not going to be magically faster than networked PD drives on GCP. The bottleneck is the same, the length of the cable between the two hosts.
At a huge price, EBS can finally get you near-local-nvme performance. If you use an io2 drive attached to a sufficiently sized r5b instance (and I think a few other instance types), you can achieve 260,000 IOPS and 7,500 MB/s throughput.
But up until the last year or two, you couldn't get anywhere near that with EBS and I'm sure as hardware advances, EBS will once again lag and you'll need to come up with similar solutions to remedy this.
Also, I guess AWS would fight them a little less here: the lack of live migrations at least means that a local failed disk is a failed disk and you can keep using the others.
google cloud also has a metric ton of IOPs and throughput on their networked persistent disks. But what this article is talking about is latency.
What are the latency characteristics like for io2? You’re mentioning near-local-nvme performance, but describing throughput (IOPS can be deceptive as they are pipelined, and as such could still give you 2ms latency at times).
Apparently io2 Block Express (I'm not sure what's the difference from io2) is capable of "sub-millisecond average latency"[0].
[0]: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/provisio...
I have this same conversation about AWS autoscaling all too frequently. It is a cost control mechanism, not a physics cheat. if you suddenly throw a tidal wave of traffic at a server then that traffic is going to queue and/or drop until there are more servers. If you saturate the network before the CPU (which is easy to do with nginx) or your event loop is too slow to accept the connections so they are dropped without being processed (easy to do I nodejs) then you might not scale at all.
I don't think it's the cable length: 0.5ms is 150km in fiber or about 100km in copper. Cable length is important in HFT where you are measuring fractions of micro seconds.
It's really quite amazing to me that HFT reduces RPC latency by about three orders of magnitude, I feel like there are lessons from there that are not being transferred to the tech world.
Both GCP and AWS provide super fast and cheap, but fallible local storage. If running an HA database, the solution is to mitigate disk failures by clustering at the database level. I've never operated scylladb before, but it claims to support high-availability and various consistency levels so the normal way to deal with this problem is to use 3 servers with fast local storage and replace an entire server when the disk fails.
A public cloud exists to serve majority usecases, not to provide you with all the options. High speed, low latency network block io is probably not a common need at this point in time.
Its very common issue. Decreasing transaction execution times for any type of request is the main goal for any data processing platforms.
I'm curious as to why with a system like Scylla (that I assume shares the same replication properties as Cassandra which my experience is based off of here) you can't just use the local SSDs and absorb the disk failures. If you space things out across AZs you wouldn't expect to lose quorum and can rebuild dead servers without issue. Is this to run things with a replication factor of 1 or something?
I've done this in past roles on AWS with their i3, etc. family with local attached storage and didn't use EBS.
This is indeed what we (ScyllaDB) do, pretty much everywhere. It works great for 95% of our users. Discord wanted to add a level of guarantee since they observed a too high level of local disk failures.
Yikes! Wonder what's up with GCP in that regard.
Basically they need to solve local SSDs not having all needed features and persistent disks having too high latency by:
> essentially a write-through cache, with GCP's Local SSDs as the cache and Persistent Disks as the storage layer.
I found it worth noting that the cache is primarily interested through linux's built in software raid system, md. SSDs in raid0 (strip), persistent disk in raid1 (mirror).
Not just a mirror but a specific setup of the mirror where it does its best to only write to one of the mirror devices, unless the other starts reporting read errors. This way they don't lose data, errors get handled gracefully and they can still snapshot the high latency disks for replication/migration tasks. That write-mostly feature was not something I was aware existed but it sounds absolutely perfect for a lot of use cases.
You mean "read from one of the mirror devices".
Yep, complete brain fart when typing that up.
Key sentence and a half:
'Discord runs most of its hardware in Google Cloud and they provide ready access to “Local SSDs” — NVMe based instance storage, which do have incredibly fast latency profiles. Unfortunately, in our testing, we ran into enough reliability issues'
Don't all physical SSDs have reliability issues? There's a good reason we replicate data across devices.
Well NVME drives shouldn't fail at a high rate, but if they don't have good local storage capabilities, then yes they have to build something else that is different.
How does NVME make local storage more reliable?
Cascading failures in drives is a fairly common occurrence unless you're actively trying to avoid it. People will typically just buy several of the same drive, from the same source, because it's easy and seems to make sense. What you've likely done is bought several of the same drive, from the same manufacturing batch, and then brought them all online at the same time. If there's a manufacturing issue, or just an expected lifetime for those drives, you're going to hit at almost the same moment across all your drives.
The ideal here is to buy similarly specced drives from multiple manufacturers to reduce the risk. At the very least buy from multiple suppliers to reduce your risk of getting drives from the same batch if this is something you're going to care about.
"Well NVME drives shouldn't fail at a high rate"
What is it about NVME that means they shouldn't fail at a high rate? I don't understand how the protocol should matter much.
An easy way I usually solve this with most MongoDB deployments is to have a couple data-serving nodes per shard that have local NVME drives and then have a hidden secondary that just uses an EBS volume with point-in-time backups.
Your write load is already split up per-shard in this scenario, so you can horizontally scale out or increase IOPS of the EBS volumes to scale. And you can recover from the hidden secondaries if needed.
And no fancy code written! :)
(by the way, feel free to shoot me an email if you need help with Mongo performance stuff!)
Clever trick. Having dealt with very similar things using Cassandra, I'm curious how this setup will react to a failure of a local Nvme disk.
They say that GCP will kill the whole node, which is probably a good thing if you can be sure it does that quickly and consistently.
If it doesn't (or not fast enough) you'll have a slow node amongst faster ones, creating a big hotspot in your database. Cassandra doesn't work very well if that happens and in early versions I remember some cascading effects when a few nodes had slowdowns.
That's good observation. We've spent a lot of time on our control plane which handles the various RAID1 failure modes, e.g. when a RAID1 degrades due to failed local SSD, we force stop the node so that it doesn't continue to operate as a slow node. Wait for part 2! :)
that's always a risk when using local drives and needing to rebuild when a node dies but I guess they can over provision in case of one node failure in cluster until the cache is warmed up
Edit: Just wanted to add that because they are using Persistent Disks as the source of truth and depending on the network bandwidth it might not be that big of a problem to restore a node to a working state if it's using a quorum for reads and RP >= 3.
Resorting a Node from zero in case of disk failure will always be bad.
They could also have another caching layer on top of the cluster to further mitigated the latency issue until the nodes gets back to health and finishes all the hinted handoffs.
We have two ways of re-building a node under this setup.
We can either re-build the node by simply wiping its disks, and letting it stream in data from other replicas, or we can re-build by simply re-syncing the pd-ssd to the nvme.
Node failure is a regular occurrence, it isn't a "bad" thing, and something we intend to fully automate. Node should be able to fail and recover without anyone noticing.
Thanks for the info that's exactly what I thought the recovery process should be. Node failure isn't bad until it's a cascading catastrophe :)
But by bad I meant when a Node is based on local disks, that Cassandra and ScyllaDB usually recommends.
Depending on the time between snapshots and the restore from snapshot process (if there are even snapshots...) can be problematic.
Bootstrapping nodes from zero depending on the cluster size (Big data nodes while not recommended are pretty common) could take days in Cassandra because the streaming implements was (maybe still is?) very bad
Doesn't streaming affect the node network? Isn't that an issue or do you have a dedicated NIC for intra node communications? or do you just limit the streaming bandwidth?
Thanks.
> While latency over a local network connection is low, it's nowhere near as low as over a PCI or SATA connection that spans less than a meter. This means that the average latency of disk operations (from the perspective of the operating system) can be on the order of a couple milliseconds, compared to half a millisecond for directly-attached disks.
uh, you can get a packet from your software on one machine, through a switch and into your software on the second machine in 1-2us if you know what you're doing
(of course, that's without any cloud bullshit like passing the packet through half a dozen levels of virtualisation, then through software defined networks)
The other replies are assuming networking in a big network is inherently slower than in a small network. I used to work at Google in Tech Infra, so I'll offer an alternate perspective while trying not to spill secrets.
First, Google has enough money that they can build their entire network out of custom hardware, custom firmware, and patch the kernel + userspace. A datacenter at Google scale is architecturally similar to a supercomputer cluster running on InfiniBand. You will never be able to replicate the performance of Google's network by buying some rackmounted servers from Dell and plumbing them together with Cisco switches.
Second, assuming a reasonably competent design, adding more machines to a network doesn't significantly increase the latency of that network. You'll see better latencies between machines in the same rack than between two racks, but this is a matter of single microseconds rather than milliseconds. Additional latency from intermediate switches is measured in nanoseconds.
Third, Google publishes an SLA on round-trip network latency between customer VMs at <https://cloud.google.com/vpc/docs/vpc>. Their "tail latencies less than 80μs at the 99th percentile" translates to ~40μs for one way, and honestly for customer VMs a lot of that happens in the customer kernel + virtualization layer. A process running on bare-metal, such as a kernel reading a remote network block device, can (IIRC) expect single-microsecond latencies to get one packet onto a nearby machine.
> The other replies are assuming networking in a big network is inherently slower than in a small network.
well yes, not true with modern switches that support cut-through forwarding
it's super-common in our space to bypass the kernel entirely, writing into the NIC buffers directly with prepared packet headers, and the card has pushed part of the packet out onto the wire, through switches and into the target machine's NIC buffers before it's even finished being written
typical "SLA"s are 0 packets dropped during a session, where a single drop raises an alert that is then investigated
> You will never be able to replicate the performance of Google's network by buying some rackmounted servers from Dell and plumbing them together with Cisco switches.
and yet, somehow we do quite a bit better (admittedly they are very, very expensive switches)
I get that people that work at Google like to think they're working on problems more advanced than those of mere mortals, but with the latencies you've described we'd be out of business several times over
(not to mention none of the clouds support multicast)
That's just different niche. I assume that you work in trading based on the word "multicast".
What Google needs is "Big+Cheaper" datacenters, and it has to work with codes written by 100000 different mere morals. What you described is in the "Small+Expensive" field, but with extreme worst-case performance demand.
"Big+Expensive" = Supercomputer "Small+Cheaper" = ??? (Note that the Big+Cheaper solutions not necessarily work for this, as you can't amortize and ignore one-time R&D/ops cost anymore)
I think you may have misread my comment.
The other replies are accepting multi-millisecond latencies as a given, and think that Google's network must be slower than even a basic copper-wired LAN because it's bigger.
My response is something like "just because the network's bigger doesn't mean it's slower".
>> You will never be able to replicate the performance of Google's network
>> by buying some rackmounted servers from Dell and plumbing them together
>> with Cisco switches.
>
> and yet, somehow we do quite a bit better (admittedly they are very,
> very expensive switches)
I take it you work in trading?
> uh, you can get a packet from your software on one machine, through a switch and into your software on the second machine in 1-2us if you know what you're doing
This isn’t a pair of servers sitting in a room with a switch in between them on a simple /24 subnet. It’s a gigantic cloud data center with a massive network spanning a huge number of devices.
The simple things you can get to work in a small setup don’t apply at this scale.
the example I gave was a simplified (though true) situation of a system local bus
it's common to have a dedicated trading network completely parallel and isolated from the main DC network for each upstream connection, of which there are dozens
and these are (at least) double redundant through the entire network, typically using redundant packet arbitration to near guarantee zero drops over a session
Google's network is super-dynamic and flexible, but slow and likely over-contended
ours is the exact opposite
> that's without any cloud bullshit like passing the packet through half a dozen levels of virtualisation, then through software defined networks
I mean, by definition, a public cloud wouldn’t work without layers of virtualization and SDN.
while i am not a "cloud expert", i'm pretty sure that google datacenters have more than one switch. furthermore, while the precise datacenter layout is probably secret, i infer that the the compute servers and the data servers cannot be housed in the same or nearby racks, since both are independently provisionable and can be arbitrarily attached. for example, if i start a vm and connect a drive, even if google could put them right next to each other in the datacenter, what happens if i start another vm, which for fragmentation reasons gets placed way on the other side of the building, detach the drive and connect it to this new one?
therefore, there must at least be several switches between the devices, and realistically, probably one or more routers.
it was an example
with modern switches it barely matters how many they are in between the machines
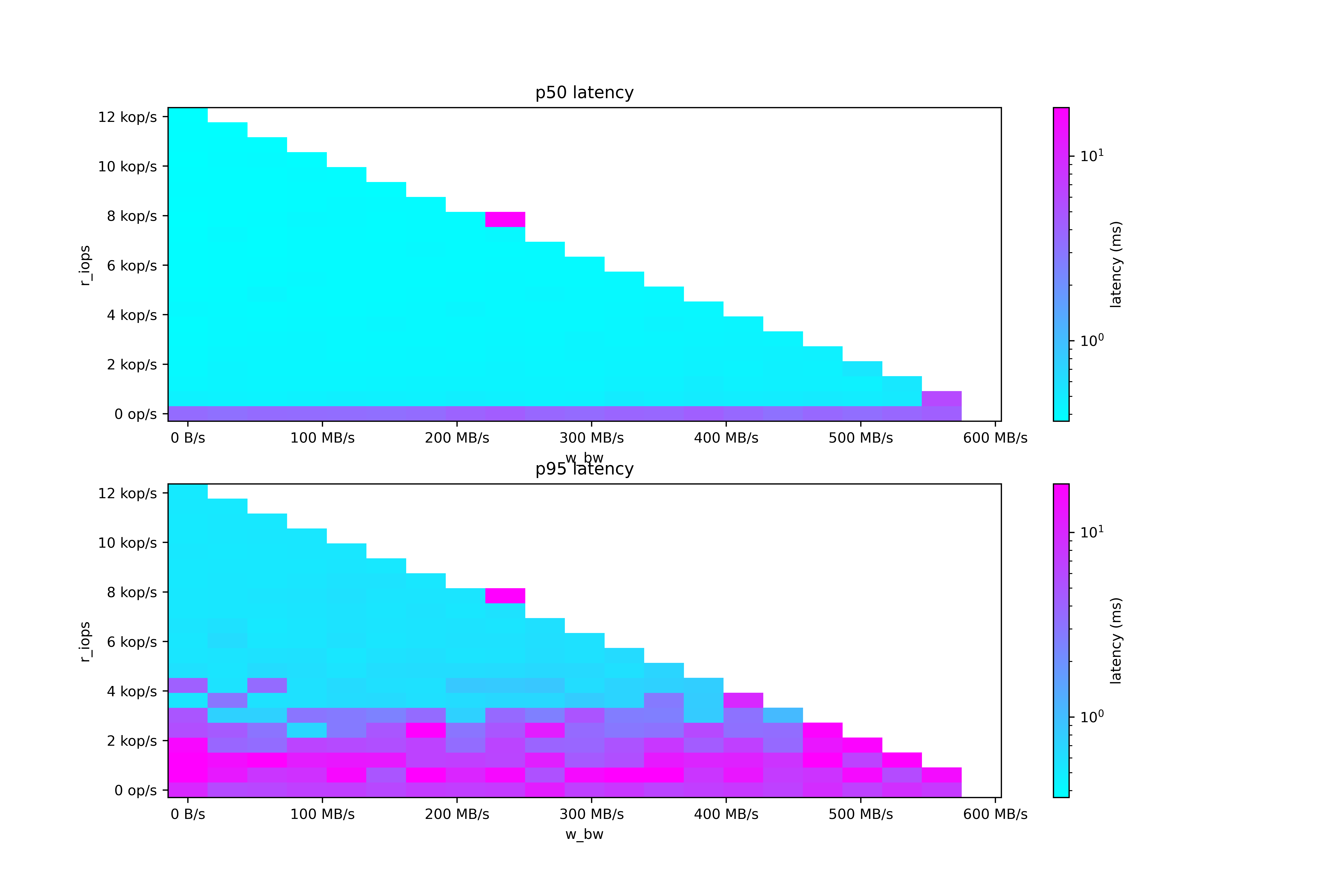
In the article, it states that after a certain point, parallelization hits limits. Is that due to Scylladb's architecture or other constraints within the system?
For reads (unless there is another bottleneck), by 10x'ing the parallelism, an application can compensate for 10x the average latency and still deliver the same throughput.
Scylladb talked about their IO scheduler a good deal:
https://www.scylladb.com/2021/04/06/scyllas-new-io-scheduler...
https://www.scylladb.com/2022/08/03/implementing-a-new-io-sc...
Naively, it seems like it should have been able to compensate for the Persistent Disk latency for read heavy workloads.
Persistent Disk read latency is usually good, but jitters up to 100ms. The scheduler can compensate for high latency (essentially applying Little's Law) but cannot compensate for jitter without saturating the disk.
Thanks. Do you see the same spikes with ebs volumes on AWS?
Some more data on Google PD: https://raw.githubusercontent.com/scylladb/diskplorer/master...
Very odd - notice how the latency is high when the read IOPS are low. When the read IOPS climb, 95th percentile latency drops.
Looks like there is a constant rate of high latency requests, and when the read IOPS climb, that constant rate moves to a higher quantile. I'd inspect the raw results but they're quite big: https://github.com/scylladb/diskplorer/blob/master/latency-m...
Background: https://github.com/scylladb/diskplorer/
Very interesting. I wonder if higher iops involves reading from more servers and with request hedging it can smooth latency a lot better.
No.
> This means that the average latency of disk operations (from the perspective of the operating system) can be on the order of a couple milliseconds, compared to half a millisecond for directly-attached disks.
While I don't know if Google offers fast storage, 0,5ms is slow compared to faster drives. 0,015ms is more around a realistic latency for faster drives with a high queue depth.
> We also lose the ability to create point-in-time snapshots of an entire disk, which is critical for certain workflows at Discord (like some data backups).
No you don't. There are multiple filesystems to choose from that support snapshots for free. Zfs is awesome.
Also, if each database has up to 1TB data and reads are the important part, why not use servers with enough memory to cache the data? That is the normal way to speed up databases that are read heavy.
I'd love to see how something like that compares to ZFS on sdb with md0 as a cache (L2ARC). Seems like it would work well as they're mainly concerned about reads.
ScyllaDB only supports XFS due to its requirement on aio.
It would all depend on what happens with a read-error on L2ARC (I have no clue).
I feel like I am missing a step. Do they write to md1 and read from md0? Or do they read from md1, and under the covers the read is likely fulfilled by md0?
I think write-through cache means they always write to both, but they try to fulfill reads using the faster device.
https://en.wikipedia.org/wiki/Write_through_cache#Writing_po...
With a write-through cache, writes are slow, but the cache is never stale. With write-back, writes can be faster, but the caches can be incoherent.
I have LVM2 set up to use my SSD as a cache for my spinner. I think it's write-through mode. Maybe.
They read from md1, which will service all requests from md0 unless it is unavailable in which case they use sdb.
Cool solution! Almost like cache wrapping a hard disk.
I am curious as to why they can’t tolerate Disk failures though, and why they need to use the Google persistent storage rather than an attached SSD for their workload.
I would have expected a fault tolerant design with multiple copies of the data, so even if a single disk dies, who cares.
Yes, RAID is all that. It's interesting to see such established technology shine and shine again.
The desire here is to avoid rebuilding a node if there is a single error in the disk no?
Because otherwise, it would make sense to just bounce the node entirely and let it build itself from the replicas.
As a database guy, the number of edge cases inherent in this model is pretty scary. I can think of several scenarios where this is really bad for your system:
* persistent data going back in time (lost the SSD, so you reload from network) * inconsistent view of the data - you wrote two pages in a related transaction. One of them is corrupted, you recover older version from the network.
That is likely to violate a lot of internal assumptions.
It’s a RAID1, so the network version is a replica of the local version. They have probably enabled write-caching on the network version, so there’s a possibility of desync but luckily that case can be handled.
This was a very interesting read. The detail on the exploratory process was perfect. Can’t wait for part two.
There's a bunch of pretty simple, old products for using SSD's to provided caching for higher latency drives that are all about ~a decade old. Some of them even use Linux's device manager or the block device subsystem explicitly...
https://github.com/mingzhao/dm-cache
https://man7.org/linux/man-pages/man7/lvmcache.7.html
https://www.kernel.org/doc/Documentation/bcache.txt
https://github.com/facebookarchive/flashcache
https://github.com/stec-inc/EnhanceIO
Doing RAID-1 (or RAID-10) style solution certainly is reasonable, but I don't understand what's novel here.
...and IIRC this is the kind of thing that btrfs and zfs were managing explicitly...
They literally mentioned the first 3 in the blog post. They said the issue with all of them was related to handling of bad sectors on the SSDs.
Yeah, I saw that. Given their "solve" though, this seems like an odd place they ended up no? They're going to have redundant copies on other machines the ScyllaDB anyway (which also has its own caching mechanism), so a failure on a read isn't that catastrophic (and in the cloud, you just spin up a new node and terminate the old one... something ScyllaDB handles very gracefully).
Yeah, I was thinking about this too. If you have to restore on a new node anyway, why have the persistent store anyway. The only reasonable answer I could think of was if they lost the whole data enter to a fire or something. They’d be able to restore the data in another zone, but that assumes they are using replicated persistent storage, which they didn’t mention. If the data isn’t replicated to another zone, this solution doesn’t make any sense.
Is it necessary to fully replicate the persistent store onto the striped SSD array? I admire such a simple solution, but I wonder if something like an LRU cache would achieve similar speedups while using fewer resources. On the other hand, it could be a small cost to pay for a more consistent and predictable workload.
How does md handle a synchronous write in a heterogenous mirror? Does it wait for both devices to be written?
I'm also curious how this solution compares to allocating more ram to the servers, and either letting the database software use this for caching, or even creating a ramdisk and putting that in raid1 with the persistent storage. Since the SSDs are being treated as volatile anyways. I assume it would be prohibitively expensive to replicate the entire persistent store into main memory.
I'd also be interested to know how this compares with replacing the entire persistent disk / SSD system with zfs over a few SSDs (which would also allow snapshoting). Of course it is probably a huge feature to be able to have snapshots be integrated into your cloud...
> Is it necessary to fully replicate the persistent store onto the striped SSD array? I admire such a simple solution, but I wonder if something like an LRU cache would achieve similar speedups while using fewer resources. On the other hand, it could be a small cost to pay for a more consistent and predictable workload.
One of the reasons an LRU cache like dm-cache wasn't feasible was because we had a higher than acceptable bad sector read rate which would cause a cache like dm-cache to bubble up a block device error up to the database. The database would then shut itself down when it encountered an disk-level error.
> How does md handle a synchronous write in a heterogenous mirror? Does it wait for both devices to be written? Yes, md waits for both mirrors to be written.
> I'm also curious how this solution compares to allocating more ram to the servers, and either letting the database software use this for caching, or even creating a ramdisk and putting that in raid1 with the persistent storage. Since the SSDs are being treated as volatile anyways. I assume it would be prohibitively expensive to replicate the entire persistent store into main memory. Yeah, we're talking many terabytes.
> I'd also be interested to know how this compares with replacing the entire persistent disk / SSD system with zfs over a few SSDs (which would also allow snapshoting). Of course it is probably a huge feature to be able to have snapshots be integrated into your cloud... Would love if we could've used ZFS, but Scylla requires XFS.
Is it really a problem to bubble up that error (and kill the database server) if you can just bring up a new database server with a clean cache (potentially even on the same computer without rebooting it) instantly? (I have been doing this kind of thing using bcache over a raid array of EBS drives on Amazon for around a decade now, and I was surprised you were so concerned about those read failures so heavily to forgo the LRU benefits when to me your solution sounds absolutely brutal for needing a complete copy of the remote disk on the local "cache" disk at all times for the RAID array to operate at all, meaning it will be much harder to quickly recover from other hardware failures.)
> Is it really a problem to bubble up that error (and kill the database server) if you can just bring up a new database server with a clean cache (potentially even on the same computer without rebooting it) instantly?
Our estimations for MTTF for our larger clusters would mean there'd be a risk of simultaneous nodes stopping due to bad sector reads. Remediation in that case would basically require cleaning and rewarming the cache, which for large data sets could be on the order of an hour or more, which would mean we'd lose quorum availability during that time.
> to me your solution sounds absolutely brutal for needing a complete copy of the remote disk on the local "cache" disk at all times for the RAID array to operate at all, meaning it will be much harder to quickly recover from other hardware failures.) In Scylla/Cassandra, you need to run full repairs that scan over all of the data. Having an LRU cache doesn't work well with this.
Curious what the perf tradeoffs are of multiple EBSes vs. a single large EBS? I know of their fixed IOPs-per-100Gb ratio or whatnot, maybe there is some benefit to splitting that up across devices.
Is it about the ability to dynamically add extra capacity over time or something?
Yeah: I do it when the max operations or bandwidth per disk is less than what I "should get" for the size and cost allocated. I had last done this long enough ago that they simply had much smaller maxes, but I recently am doing it again as I have something like 40TB of data and I split it up among (I think) 14 drives that can then be one of the cheapest EBS variants designed more for cold storage (as the overall utilization isn't anywhere near as high as would be implied by its size: it is just a lot of mostly dead data, some of which people care much more about).
Thanks for the insights!
Is the bad sector read rate abnormally high? Are GCE's SSDs particularly error prone? Or is the failure rate typical, but a bad sector read is just incredibly expensive?
I assume you investigated using various RAID levels to make an LRU cache acceptably reliable?
It's also surprising to me that GCE doesn't provide a suitable out of the box storage solution. I thought a major benefit of the cloud is supposed to be not having to worry about things like device failures. I wonder what technical constraints are going on behind the scenes at GCE.
> Are GCE's SSDs particularly error prone?
Yes, incredibly error prone. Bad sector reads were observed at an alarming rate over a short period - well beyond what is expected if you were to just buy an enterprise nvme and slap it into a server.
That's quite an indictment of GCP if their Local SSD's reliability is that bad.
How does this setup handle a maintenance of the underlying hypervisor host? As far as I know the VM will be migrated to a new hypervisor and all data on the local SSDs is lost. Can the custom RAID0 array of local SSDs handle this or does it have to be manually rebuilt on every maintenance?
On GCP, live migration moves the data on the local-ssd to the new host as well.
Oh nice, that's really cool. I am pretty sure last time I checked this was not the case (~2 years ago)
From the article:
> GCP provides an interesting "guarantee" around the failure of Local SSDs: If any Local SSD fails, the entire server is migrated to a different set of hardware, essentially erasing all Local SSD data for that server.
I wonder how md handles reads during the rebuild, and how long it takes to replicate the persistent store back onto the raid0 mirror.
I wonder how does this look from the host's perspective? Does the SSD disappear (from a simulated SATA bus that supports hot plug) and reappear? Does it just temporarily return read errors before coming back to life but the underlying blocks have silently changed (I hope not)? Etc.
I assume the host moves, not the disks. My next assumption is that the host moving would involve downtime for the host, so no need to bother simulating some hotplugs.
(I know that live migrations are at least in theory possible, but I don’t know why GCP would go through all the effort)
(I’m also making a lot of assumptions about things I am not an expert in)
The disks are physically attached to the host. The VM running on that host moves from one host to another. GCP live-migrates every single VM running on GCP roughly once per week, so live migration is definitely seamless. Standard OSS hypervisors support live migration.
When hardware fails, the instance is migrated to another machine and behaves like the power cord was ripped out. It's possible they go down this path for failed disks too, but it's feasible that it is implemented as the disk magically starting to work again but being empty.
You can read more about GCP live migrations here: https://cloud.google.com/compute/docs/instances/live-migrati...
When a local disk fails in an instance, you end up with an empty disk upon live migration. The disk won't disappear, but you'll get IO errors, and then the IO errors will go away once the migration completes but your disk will be empty.
When standard filesystems like ext4 and xfs hit enough io errors,they unmount the filesystem. I find that this happens pretty reliably in AWS at least and I can't imagine the filesystem possibly continuing to do very much when 100% of the underlying data has disappeared.
That said, from further reading of the GCP docs, it does sound like if they detect a disk failure they will reboot the VM as part of the not-so-live migration.
Yes, under a graceful live migration with no hardware failure, the data is seamlessly moved to a new machine. The problem of moving local data is ultimately no different that live migrating the actual RAM in the machine. The performance does degrade briefly during the migration, but typically this is a very short time window.
You can read more about GCP live migrations here: https://cloud.google.com/compute/docs/instances/live-migrati...
This is quite clever. I had tried a simpler version of this a few years back on AWS using LVM cache[1], attached SSD disks (for the cache) and EBS volumes (for the persistent storage). For our workloads (big data processing with Hadoop/Hive), the performance benefit was not significant, so we dropped it.
1. https://access.redhat.com/documentation/en-us/red_hat_enterp...
Regarding ScyllaDB:
> while achieving significantly higher throughputs and lower latencies [compared to Cassandra]
Do they really get all that just because it's in C++? Anyone familiar with both of them?
Cassandra is written in Java and while there are a lot of tricks to optimize it there are limits.
While C++ does have an advantage of raw performance it's ScyllaDB's seastar implementation that helps a lot. Think of every core in the machine as a node so there is no context switching and better use of the cpu cache. More than that the ScyllaDB team are extremely performance focused something that I can't say for Cassandra
It's the architectural choices more than the language (one thread per core, async, event loops). But I'm sure the c++ does have some benefit over Java.
I wonder how many times fsync (or equiv) is called for this. Because IO load typically heavily depends on write queuing and syncing smartly (see other databases). The article does not describe this in detail, but it feels like the assumption and requirement is to fsync for every write operation separately (instead e.g. of combining).
Curious if Discord considered using FoundationDB. Its read performance is pretty good and its replicated, distributed nature would also protect from data failure to an extent.
My takeaways:
- Cloud vendors should offer a hosted "Superdisk" so users don't have to implement themselves.
- Reading good engineering blog posts can save you the trouble of having to re-learn their experiences!
What's nice about what Discord did is that it's just a Linux Kernel config hack. That's a different layer of abstraction than <insert-favorite-db-here> since you can just use the filesystem.
They're already using a replicated data store. The issue was with raw-SSD's, the failure rate was too high and could cause instability given too many hosts could be down at once.
Cool. Maybe I am missing something, but I have seen other solutions where data is mirrored to local ephemeral disks in the cloud. The problem with that is it affects the overall performance of the VM during mirroring when there is a new disk. Is this avoided somehow with RAID?
That's a very smart solution indeed. I wonder if it is also possible to throw more memory at the problem? Managing instances with locally attached disks on the cloud is a bit of a pain, as you don't have the capability to stop/start the instances anymore.
I didn't know about md and this "write-mostly" option, that is a pretty neat setup.
It looks like Google's persistent networked disks perform worse than AWS's. I typically see sub-1ms latency on GP2 disks even under load. GP3 is usually a little higher but still under 1ms.
would've really known how much cpu this solution would cost. most of the time mdraid adds additonal cpu time (not that it matters to them that much)
If it’s just raid0 and raid1, then there’s likely not any significant CPU time or CPU overhead involved. Most southbridges or I/O controllers support mirroring directly, and md knows how to use them. Most virtualized disk controllers do this in hardware as well.
CPU overhead comes into play when you’re doing parity on a software raid setup (like md or zfs) such as in md raid5 or raid6.
If they needed data scrubbing at a single host level like zfs offers, then probably CPU would be a factor, but I’m assuming they achieve data integrity at a higher level/across hosts, such as in their distributed DB.
well we do use md raid on raid10 on nvme disks and on write heavy workloads it can quickly raise cpu usage tough (few percent) thats why I'm asking. it might also be a problem that we have two cpu's and we probably go over multiple i/o controllers tough (and we do not care since we are not really cpu bound, so we have plenty to spare, our workload is more i/o,memory heavy
The database should be able to be configured with a cache device.
Using a RAID manager or a filesystem for this does not seem optimal.
Actually, using Something like ReadySet[1] but using a swap drive instead of memory to store the cached row would work very well.
What I am curious about after reading the article is how do they automate the deployment of this setup?
Disk IO latency (in other words QD1 IOPS) is underrated metric on cloud.
It sounds like intel optane persistent memory could work here
Sadly Optane cost a fortune, was never available in most clouds, and has now been canceled.
Gotta supercharge indeed for that sweet, sweet personal user data and metadata, right, Discord?
It's certainly not the place to talk if you value your and your peers' safety.
As an aside, I'm always impressed by Discord's engineering articles. They are incredibly pragmatic - typically using commonly available OSS to solve big problems. If this was another unicorn company they would have instead written a custom disk controller in Rust, called it a Greek name, and have done several major conference talks on their unique innovation.
They've probably subscribed to Taco Bell Programming.
http://widgetsandshit.com/teddziuba/2010/10/taco-bell-progra...
>> http://widgetsandshit.com/teddziuba/2010/10/taco-bell-progra...
> Here's a concrete example: suppose you have millions of web pages that you want to download and save to disk for later processing. How do you do it? The cool-kids answer is to write a distributed crawler in Clojure and run it on EC2, handing out jobs with a message queue like SQS or ZeroMQ.
> The Taco Bell answer? xargs and wget. In the rare case that you saturate the network connection, add some split and rsync. A "distributed crawler" is really only like 10 lines of shell script.
I generally agree, but it's probably only 10 lines if you assume you never have to deal with any errors.
Errors, retries, consistency, observability. For actual software running in production, shelling out is way too flaky and unobservable
Can I, with off the shelf OSS tooling, easily trace that code that’s “just wget and xargs”, emit metrics and traces to collectors, differentiate between all the possible network and http failure errors, retry individual requests with backoff and jitter, allow individual threads to fail and retry those without borking the root program, and write the results to a datastore in idempotent way, and allow a junior developer to contribute to it with little ramp-up?
It’s not about “can bash do it” it’s about “is there a huge ecosystem of tools, which we are probably already using in our organization, that thoroughly cover all these issues”.
It depends on what you mean by ‘production’ of course.
Plenty of stuff runs in production as shell scripts at Google - if you’re a dev, you just don’t notice it often.
Most of the rest of the glue is Python.
Not only processing and generating, but also running up phone bills, like uucp!
That can be solved at the design level: write your get step as an idempotent “only do it if it isn’t already done” creation operation for a given output file — like a make target, but no need to actually use Make (just a `test -f || …`.)
Then run your little pipeline in a loop until it stops making progress (`find | wc` doesn’t increase.) Either it finished, or everything that’s left as input represents one or more classes of errors. Debug them, and then start it looping again :)
Having that logic in the same place as the work of actually driving the fetch/crawl, though, is a violation of Unix “small components, each doing one thing” thinking.
You know how you can rate-limit your requests? A forward proxy daemon that rate-limits upstream connections by holding them open but not serving them until the timeout has elapsed. (I.e. Nginx with five lines of config.) As long as your fetcher has a concurrency limit, stalling some of those connections will lead to decreased attempted throughput.
(This isn’t just for scripting, either; it’s also a near-optimal way to implement global per-domain upstream-API rate-limiting in a production system that has multiple shared-nothing backends. It’s Istio/Envoy “in the small.”)
What happens if a page is partially downloaded?
I’d add GNU parallel to the tools used; I’ve written this exact crawler that way, saving screenshots using ghostscript, IIRC
Isn't that also only an incredibly simplified crawler? I can't see how that works with the modern web. Try crawling many websites and they'll present difficulties such that when you go to view what you've downloaded you realise it's useless.
Fair, but a simply Python script could probably handle it. Still don't need a message queue.
The truth is, though, that aws and the other cloud providers that have more than hosted storage and compute, are building their own “operating system” to build these systems.
We Unix graybeards may be used to xargs, grep and wget. The next generation of developers are learning how to construct pipelines from step functions, sqs, lambda and s3 instead. And coming as someone who really enjoys Unix tooling, the systems designed with these new paradigms will be more scalable, observable and maintainable than the shell scripts of yore.
Well, yeah.
I think cloud gets much maligned — but all the serious discussions with, eg, AWS employees work from this paradigm:
- AWS is a “global computer” which you lease slices of
- there is access to the raw computer (EC2, networking tools, etc)
- there are basic constructs on top of that (SQS, Lambda, CloudWatch, etc)
- there are language wrappers to allocate those for your services (CDK, Pulumi, etc)
…and you end up with something that looks surprisingly like a “program” which runs on that “global computer”.
I know that it wasn’t always like that — plenty of sharp edges when I first used it in 2014. But we came to that paradigm precisely because people asked “how can we apply what we already know?” About mainframes. About Erlang. About operating systems.
I think it’s important to know the Unix tools, but I also think that early cloud phase has blinded a lot of people to what the cloud is now.
All the crawler needs to be is a quick crawler script, a Typescript definition of resources, and you get all the AWS benefits in two files.
Maybe not “ten lines of Bash” easy, but we’re talking “thirty lines total, with logging, retries, persistence, etc”.
The article is from 2010 and uses the term DevOps! Just how long has that meme been around?
Oooh, I like this. I gotta remember this term.
Awesome article!
Discord has done its fair share of RIIR though[0][1] ;)
[0] https://discord.com/blog/why-discord-is-switching-from-go-to...
[1] https://discord.com/blog/using-rust-to-scale-elixir-for-11-m...
This. This 100%. I’m exhausted by how this has become the norm, it’s such an endemic issue in the tech industry that even rationally minded people will disagree when pragmatic solutions are proposed, instead suggesting something harder or “more complete” to justify why our solution is better or more valuable. Complexity kills, but people really enjoy building complex things.
There are some times when writing a custom solution does make sense though.
In their case, I'm wondering why the host failure isn't handled at a higher level already. A node failure causing all data to be lost on that host should be handled gracefully through replication and another replica brought up transparently.
In any case, their usage of local storage as a write through cache though md is pretty interesting, I wonder if it would work the other way around for reading.
Scylla (and Cassandra) provides cluster-level replication. Even with only local NVMes, a single node failure with loss of data would be tolerated. But relying on "ephemeral local SSDs" that nodes can lose if any VM is power-cycled adds additional risk that some incident could cause multiple replicas to lose their data.
It seems that the biggest issue then is that the storage primitives that are available (ephemeral local storage and persistent remote storage) make it hard to have high performance and highly resilient stateful systems.
That's a common theme here. We try to avoid making tools into projects.
Huh, maybe Greek named Rust disk controller would be better. Since it's not written we do not know one way or the other. Besides all these messaging/chat apps have same pattern: Optimize on the cloud/server side, peddle some electron crap on client side and virtue signal all the way about how serious are they about engineering(on server side).
Agreed, I thought this was a great writeup about how they solved an interesting problems with standard, battle-tested Unix tools.
Related, I hope GCP is listening and builds an "out-of-the-box" solution that automatically combines this write-through caching solution into one offering. Just like I shouldn't have to worry (much) about how the different levels of RAM caching work on a server, I shouldn't have to worry much about different caching layers of disk in the cloud.
This is only pragmatic if you accept the first order assumption that they must use GCP. Which, maybe it's the case for a dev at Discord, but it's a somewhat idiosyncratic choice to call pragmatic. Seems like a lot of developer time and GCP charges to overcome limitations of GCP and wind up with something that's far more brittle than just running your databases on real hardware.
They already run on gcp and presumably have a negotiated agreement on pricing. Their core competencies don’t include managing hardware. Migration off is deliberately expensive and hard. Own hardware still needs a story for backup and restore in lieu of attached volume snapshots, or they’d have to figure out if their database can do something for them there. Any of the above are good reasons to not migrate willy nilly, in fact the only reason to migrate is that either you can’t do what you need to in the cloud or the margins can’t support it.
Ironically, Discord rewrote all of their messaging centric services from Go to Rust due to pretty niche GC issues.
> Pragmatic
> Rewrite it in Rust
Idk, I don't see the irony here
4 billion messages sent through the platform by millions of people per day
I wish companies would stop inflating their numbers by citing "per day" statistics. 4 billion messages per day is less than 50k/second; that sort of transaction volume is well within the capabilities of pgsql running on midrange hardware.
Absolutely not. This is an average, I bet their peak could be in the mid hundreds of thousands, imagine a hype moment in a LCS game.
It can in theory work, but the real world would make this the most unstable platform of all the messaging platforms.
Just one vacuum would bring this system down, even if it wasn't an exclusive lock... Also I would be curious how you would implement similar functionality to the URL deep linking and image posting / hosting.
Mind you the answers to these will probably increase average message size. Which means more write bandwidth.
Some bar napkin math shows this would be around 180GiB per hour, 24/7, 4.3TiB per day.
Unless all messages disappeared within 20 days you would exceed pretty much any reasonable single-server NVME setup. Also have fun with trim and optimizing NVME write performance. Which is also going to diminish as all the drives fail due to write wear...
Absolutely not. This is an average, I bet their peak could be in the mid hundreds of thousands
That's my point. Per-second numbers are far more useful than per-day numbers.
> useful than per-day numbers
Useful for what exactly? You're basically accusing the company of inflating their numbers (??) as if they are deliberating lying about their scale.
In a technical blog or dashboard I like to see
1) avg mean (for throughput estimates), 2) p50 (typical customer / typical load), 3) p90 / p99 / p99.99 (whatever you think your tail is) 4) p100 (max, always useful to see and know, maybe p0).
Or throw in a histogram or kernel density estimate, sometimes there are really interesting patterns.
I’ve never seen a technical blog give such traffic or latency details though.
Edit: reading other comments, please do not read this as diminishing this blog post or Discord, great clear writing and impressive solution to an interesting problem.
> blog post
It's a blog...it IS marketing.
So add a Redis node or two as cache - exactly the same kind of things they did basically.
(I work at Discord.)
It's not even the most interesting metric about our systems anyway. If we're really going to look at the tech, the inflation of those metrics to deliver the service is where the work generally is in the system --
* 50k+ QPS (average) for new message inserts * 500k+ QPS when you factor in deletes, updates, etc * 3M+ QPS looking at db reads * 30M+ QPS looking at the gateway websockets (fanout of things happening to online users)
But I hear you, we're conflating some marketing metrics with technical metrics, we'll take that feedback for next time.
Ideally I'd like to hear about messages per second at the 99.99th percentile or something similar. That number says far more about how hard it is to service the load than a per-day value ever will.
Wouldn’t a single second slice be of limited value compared to 30+ second samples?
What a myopic comment.
> 50k/second
Yes, 50k/second for every minute of the day 365/24/7. Very few companies can quote that.
Not to mention:
- Has complex threaded messages
- Geo-redundancies
- Those message are real-time
- Global user base
- Unknown told of features related to messaging (bot recations, ACL, permissions, privacy, formatting, reactions, etc.)
- No/limited downtime, live updates
Discord is technically impressive, not sure why you felt you had to diminish that.
Geo redundancies? Discord is all in us-east-1 gcp. Unless you Meant AZ redundancy?
> We are running more than 850 voice servers in 13 regions (hosted in more than 30 data centers) all over the world. This provisioning includes lots of redundancy to handle data center failures and DDoS attacks. We use a handful of providers and use physical servers in their data centers. We just recently added a South Africa region. Thanks to all our engineering efforts on both the client and server architecture, we are able to serve more than 2.6 million concurrent voice users with egress traffic of more than 220 Gbps (bits-per-second) and 120 Mpps (packets-per-second).
I don't see anything on their messaging specifically, just assuming they would have something similar.
https://discord.com/blog/how-discord-handles-two-and-half-mi...
You may consider regioning guilds by the region of the guild owner's ToS/billing address.
I don’t think discord needs geo redundancy :)
Is there a template for replying to hackernews posts linking to engineering articles?
1. Cherry pick a piece of info 2. Claim it's not that hard/impressive/large 3. Claim it can be done much simpler with <insert database/language/hardware>
I mean they literally list the per second numbers a couple paragraph down:
>Our databases were serving around 2 million requests per second (in this screenshot.)
I doubt pgsql will have fun on mid-range hardware with 50k writes/sec, ~2 million reads/sec and 4 billion additional rows per day with few deletions.
actually 'few deletions' and 'few updates' is basically the happy case for postgres. MVCC in a append only system is where it shines. (because you generate way less dead tuples, thus vacuum is not that big of a problem)
That's only messages sent. The article cites 2 million queries per second hitting their cluster, which are not served by a CDN. Considering latency requirements and burst traffic, you're looking at a pretty massive load.
50k/s doesn't tell us about the burstiness of the messages. Most places in the US don't have much traffic at 2AM
TL;DR - NAS is slow. RAID 0 is fast.
This is not an accurate summary of the article.
At this point, seems they’d be better off with colo + own hardware.
If they weren’t comfortable with the durability/availability of local SSDs in the cloud, why would they be comfortable with that plus more with their own hardware?
That said, I don’t totally disagree with you that maybe collocating would be worth it. But they were very clear that they like offloading the work of durable storage to GCP. And they found a pretty elegant solution to achieve the best of both worlds.
Also, FWIW, Discord does offload some workloads to their own hardware. (Or so I’m told, I don’t work there but I know people who do)
Oh look they rediscovered RAID 0+1
Discord is abyssmally slow compared to the IRC I use.
It is the height of chutzpah to talk about supercharging and extreme low latency, when the end user experience is so molasses slow.
> Local SSDs in GCP are exactly 375GB in size
Ouch! My SSD from a decade ago is larger than that, and probably, more performant.
IRC daemons aren't saving PRIVMSGs and other events to disk. They send them to the target user/channel and then that memory is freed. This comparison makes no sense.
Some do save them to disk:
* https://www.unrealircd.org/docs/Channel_history
* https://docs.inspircd.org/3/modules/chanhistory/
* https://github.com/ergochat/ergo/blob/master/docs/MANUAL.md#...
And they are not niche servers; UnrealIRCd and InspIRCd are the top two in terms of deployments according to https://www.ircstats.org/servers
Interesting! +H wasn't a thing when I stopped using IRC/writing bots. InspIRCD (and its amusing default config file) was the daemon I always used. Looks like my client of choice (irssi) never added support for this feature.
InspIRCd's +H does not depend on client support; when configured it sends the history on join to all clients (except those which marked themselves as bot with mode +B). What irssi lacked though is the "server-time" extension, which means it would display the wrong timestamp for history messages.
From what I understand, IRC is decentralized whereas Discord hosts every chat. Not comparable.
Discord offers a lot more features too.
Enterprise ssd is not the same as a consumer one.
The enterprise SSDs are huge compared to consumer ones, as in 100TB sized.
Q about a related use case: Can I use tiered storage (e.g., SSD cache in front of a HDD with, say, dm-cache), or an md-based approach like Discord's, to successfully sync an Ethereum node? Everyone says "you should get a 2TB SSD" but I'm wondering if I can be more future-proof with say 512 GB SSD cache + much larger HDD.
I'm not familiar with what Ethereum requires for its syncing operation.
If it's a sequential write (by downloading the entire blockchain), you will still be bottlenecked by the throughput of the underlying disk.
If it's sequential reads (in between writes), the reads can be handled by the cache if the location is local enough to the previous write operation that it hasn't been evicted yet.
If it's random unpredictable reads, it's unlikely a cache will help unless the cache is big enough to fit the entire working dataset (otherwise you'll get a terrible cache hit rate as most of what you need would've been evicted by then) but then you're back at your original problem of needing a huge SSD.
If your hardware sucks, try Akula instead of geth/erigon. It can supposedly sync on spinning rust with low IOPS.
Unless you're running a full archive node, you don't need 2tb. My geth dir is under 700gb. Do a snap sync then turn on archive mode if you only need data moving forward from some point in time.
Sure, you might want to look into bcache or bcachefs.
This reads less like a story about how clever Discord engineers are, and more like how bad GCP is!
In Azure, I don't have to worry about any of this. There's a flag to enable read-only or read-write caching for remote disks, and it takes care of the local SSD cache tier for me! Because this is host-level, it can be enabled for system disks too.
But at least I have a case study that NoSQL scales for an application way larger than anything we’ll ever do
ScyllaDB users typically start at a few hundred GBs of data and scale to TBs over time. The good news is no matter what scale you start at you won't hit a wall on an upper bound.
Disclosure: I work at ScyllaDB.
They need to put more work into the client instead of wasting engineering hours on the backend. Literally the biggest bottleneck that makes the computer feel like it was from decades ago is the nonsensical piece of crap that is the client. Build an actual UI that doesn’t misuse web technologies in the first place rather than talk about supercharging anything.
{kind=link}
Thanks for the clarification, I consider myself fairly well informed about server hardware and had no idea that there were transport methods for NVMe other than PCI Express.
There were a slew of new NVMe specs that came out last year, such as the separation of storage and transport. So now NVMe has the following transport protocols:
• PCIe Transport specification
• Fibre Channel Transport specification (NVMe-oF)
• RDMA Transport specification
• TCP Transport specification
Separation of storage from transport is a huge game changer. I am really hoping NVMe-over-fibre really takes off. But I'd suggest people would first see that in on-prem deployments before you see it in the cloud-hosting hyperscalers.
More on the 80,000 foot view of what's going on in NVMe world is covered in link below. But there are tech specs you can read over if you are so interested in how exactly it works.
https://nvmexpress.org/nvm-express-announces-the-rearchitect...
[EDIT: Also, the GCP persistent disks are not NVMe-oF as far as we know. They seem to be iSCSI based off Colossus/D. see: https://news.ycombinator.com/item?id=21732387]
It seems like expected confusion. The protocol is well suited for a wide/fast path, so people associate it with something local that uses a lot of PCI lanes, which is much faster/wider/lower-latency than your NIC.
But why then would the article mention that they had problems with reliability? That seems ... odd; what have you experienced in your working with these (assuming you have)?
These disks aren't typically meant for database server usage. They're fine for consumers and even stuff like webservers, but the amount of data discord moves around on the daily means that they are bound to make some disks fail pretty quickly.
The normal course of action for this is usually to have a raid array over all your nvme disks, but since google just migrates your VM to a machine that has good disks, doing that is useless.
Really this whole article is "we are going to keep using google cloud despite their storage options being unfit for our purpose and here's how".
> Really this whole article is "we are going to keep using google cloud despite their storage options being unfit for our purpose and here's how".
And that's called hacking. Welcome to Hacker News. Discord's engineers are gods among mortals for squeezing this kind of latency and reliability out of something Google intended for consumers. Yes I know the way you're supposed to do something like this is to use something like Cloud BigTable where you probably have to call a salesperson and pay $20,000 before you're even allowed to try the thing. But Discord just ignored the enterprisey solution and took what they needed from the consumer tools instead. It reminds me of how early Google used to build data centers out of cheap personal computers.
Consider it is not an unheard of experience to join the workforce, use a preconfigured macbook with precisely 1 SSD, and spend one's career building on SaaS platforms like AWS Lambda.
In such a world, perhaps those who remember there's a world of flexibility and power within the OS could be seen as welding some supernatural power.
More charitably, the GP could be suggesting that Discord should have gone to a lower layer in the stack by using their own hardware, which would let them choose a more appropriate storage substrate instead of layering on top of an inappropriate one.
google might see this and add it as an offering with cost lower than bigtable
> Really this whole article is "we are going to keep using google cloud despite their storage options being unfit for our purpose and here's how".
Hmm, I read it more like they figured out a way to scale their existing storage a bit better while making Google eat the cost.
It’s not like they pay extra if they wear out the disks sooner.